
Introduction: Another AI Model, Another Wave of Promises
When Anthropic announced Claude 4 this spring, the AI world once again hit peak hype. Just like the buzz around GPT-5, Gemini Ultra, and every shiny new “state-of-the-art” LLM that claims to reinvent productivity, the promise was huge:
- Smarter coding agents
- Deeper reasoning
- More stable outputs
- Safer responses
I’ve been working with AI coding assistants daily—living inside VS Code, Cursor, Windsurf, GitHub Copilot, and even writing my own wrappers around APIs. So when Claude 4 dropped, I decided to run it through the wringer.
This review is long, detailed, and brutally honest. If you’re looking for fluffy praise, stop reading now. But if you’re a developer curious about whether Claude 4 Sonnet or Opus should be part of your daily toolkit—or whether GPT-5 is the better bet—buckle up.
What Anthropic Promised with Claude 4
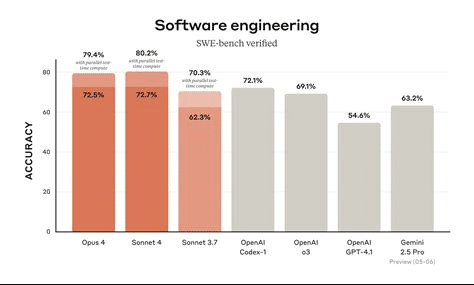
Anthropic released two major Claude 4 variants:
- Claude Opus 4: The flagship, meant for deep reasoning, long-horizon tasks, and complex agents.
- Claude Sonnet 4: A lighter, cheaper model, aimed at daily workflows and integrations like GitHub Copilot.
Key highlights from the launch:
- Extended Thinking (internal reasoning summaries, ~5% trigger rate)
- Memory + File Handling improvements
- Tool Use & Agents with Sonnet optimized for Copilot
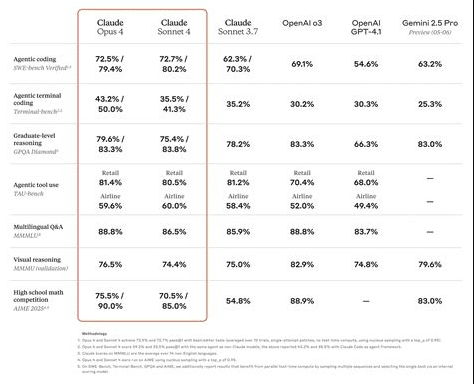
- Benchmarks like 72.7% SWE-bench, fewer “shortcut behaviors”
On paper, it sounded incredible. Anthropic even quoted partners saying:
“Claude code is voodoo and I’ve never seen ChatGPT come close to what it’s doing for me right now.”
Community’s First Impressions: Disappointment and Praise
Right after launch, Reddit lit up with mixed reactions. In r/LocalLLaMA, one developer bluntly wrote:
“4 is significantly worse. It’s still usable, and weirdly more ‘cute’ than the no-nonsense 3.7 … but 4 makes more mistakes for sure.”
Others mentioned issues in VS Code:
“… it occasionally gets stuck in loops with corrupted diffs constantly trying to fix the same 3 lines of code …”
But some devs found improvements:
“My results from Claude 4 have been tremendously better. It no longer tries to make 50 changes when one change would suffice … I also don’t have a panic attack every time I ask it to refactor code.”
This mixed feedback mirrors my own experience: Claude 4 shines in some contexts but stumbles in others.
Claude 4 in Coding Workflows

Code Refactoring and Diff Management
- The good: Sonnet 4 avoids shotgun rewrites, targeting smaller fixes.
- The bad: Frequent diff loops, endlessly re-editing the same lines.
In comparison, GPT-5 in Windsurf produced clean diffs and handled 400 lines of context vs Sonnet’s 50–200.
Natural Language → Code Translation
- GPT-5 more consistently translates NL → code correctly.
- Example: A Node.js recursive directory watcher. GPT-5 nailed it; Sonnet 4 needed 3+ retries.
Claude 4 as an Agent

Anthropic pitched Sonnet as an “agent-ready” model. But in deep research runs, Claude lagged. As one Redditor wrote:
“GPT-5 won by a HUGE margin when I used the API in my Deep Research agents.”
In my tests: GPT-5 produced faster, cleaner outputs. Claude Opus 4 sometimes meandered, wasting tokens.
That said, I appreciate Claude’s cautious honesty:
“This is unlikely to work because…” is often better than blind optimism.
Pricing and Cost Efficiency
- Claude Sonnet 4: $3 / $15 per million tokens (in/out).
- Claude Opus 4: $15 / $75.
- GPT-5: $1.25 / $10.
👉 GPT-5 is cheaper and stronger in coding/research. For startups burning tokens, this cost gap is painful.
Developer Experience in IDEs
Here’s a quick comparison table:
| Feature | Claude Sonnet 4 | GPT-5 |
|---|---|---|
| Diff application stability | Often loops / corrupts | Stable, clean diffs |
| Context window scanning | ~50–200 lines | ~200–400 lines |
| NL → Code accuracy | Decent but misses details | Higher precision |
| Refactoring safety | More cautious | Sometimes too aggressive |
| Agentic tasks | Prone to loops | More consistent |
| Cost | 2–3× higher | Much cheaper |
Where Claude 4 Actually Shines
- Cautious honesty in warnings.
- Smaller, safer refactors.
- Claude Code IDE integration feels smoother.
- Long-horizon memory in Opus 4 for marathon sessions.
Where It Falls Flat
- Diff loops corrupt projects.
- Limited context scanning.
- Much higher costs than GPT-5.
- Underwhelming agentic performance.
The Bigger Picture: Claude 4 vs GPT-5
- Cost + performance → GPT-5 wins.
- Safety + cautious honesty → Claude Sonnet 4 has edge.
- Long memory tasks → Opus 4 has niche value.
Neither is perfect: GPT-5 can be lazy; Claude 4 can loop.
Final Verdict: Should Developers Care About Claude 4?
Claude 4 is a step forward but not revolutionary.
- Sonnet 4 → good for safer inline IDE edits.
- Opus 4 → useful for long-memory tasks, but pricey.
- GPT-5 → best balance of cost + capability.
Think of Claude 4 as the careful junior dev, while GPT-5 is the senior engineer who delivers big when motivated.
Frequently Asked Questions
Is Claude 4 better than GPT-5 for coding?
No. GPT-5 generally performs better in code generation, context scanning, and agent tasks. Claude 4 Sonnet is safer for smaller edits.
How much does Claude 4 cost compared to GPT-5?
Claude Sonnet 4 is $3 / $15 per million tokens. Opus 4 is $15 / $75. GPT-5 is $1.25 / $10, much cheaper.
Is Claude 4 good for research agents?
Claude 4 can handle multi-hour sessions, but GPT-5 is more accurate and efficient.
Who should use Claude 4?
Sonnet 4 is best for developers who want cautious, safe code edits. Opus 4 suits long projects requiring memory, but at higher cost.
Comments